


Executive Summary
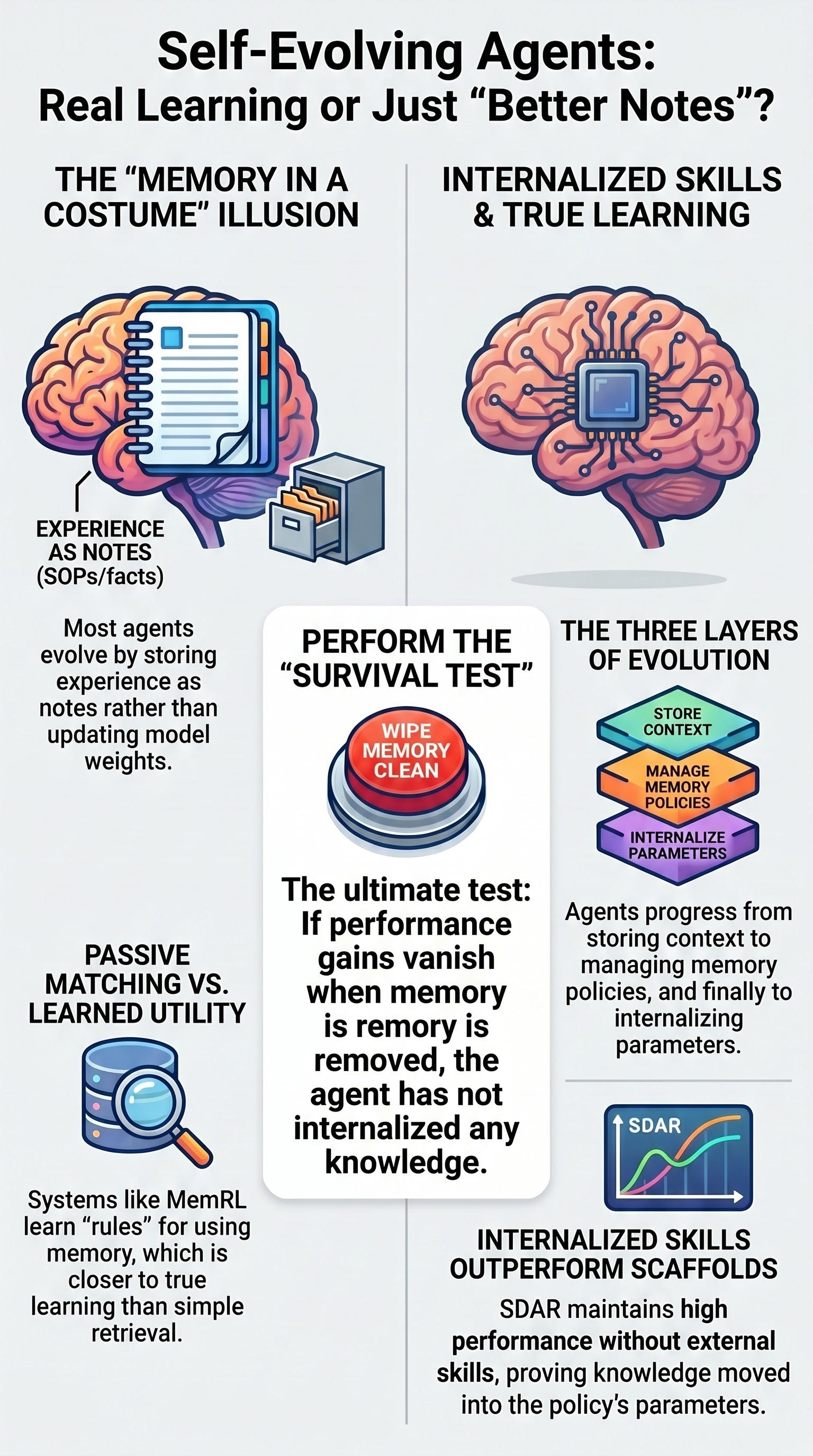
The landscape of “self-evolving agents” in 2026 is defined by a critical distinction between sophisticated memory management and genuine machine learning. While the industry frequently markets agents as “self-evolving,” the majority of these systems do not update their base model weights. Instead, they rely on memory dynamics—the ability to distill, store, rank, and reuse experience within a stateful architecture.
The core metric for evaluating these systems is the “Wipe Test”: identifying what performance gains survive if the agent’s external memory is deleted.
Memory-Centric Systems: Performance gains vanish upon memory removal; the system relies on “better notes” and context engineering.
Policy-Learned Systems: Performance gains are partially retained because the rules governing memory usage have been trained as a policy.
Internalized Systems: Performance gains survive because knowledge has been distilled into the model’s parameters (weights).
Genuine “learning” in the strong sense only occurs when the agent modifies its underlying policy or parameters, rather than simply expanding its database of experiences.
--------------------------------------------------------------------------------
The Taxonomy of Agentic Change
To understand what “self-evolution” entails, the research identifies five specific loci where an agent system can change. These categories help builders audit systems and determine the reversibility and cost of evolution.
The Five Loci of Change
Locus of Change
Description
Characteristics
Weights
Model parameters or fine-tuned controllers.
Low reversibility; high compute cost; survives memory removal.
Prompt/Core Memory
Instructions or core memory blocks.
High reversibility; low cost; immediate behavior change.
External Memory
Facts, episodes, SOPs, reasoning summaries, and graphs.
Scalable; high reversibility; primarily knowledge-based.
Management Policy
Rules for fetching, writing, updating, and deleting memory.
Can be heuristic-based or learned via Reinforcement Learning (RL).
Tool Inventory
The agent’s capability graph or available executable code.
Growth in functional reach; often categorized as “skill growth.”
--------------------------------------------------------------------------------
Memory vs. Learning: The “Costume” Spectrum
The research characterizes many self-evolving claims as “memory in a costume.” This spectrum ranges from simple data retrieval to genuine parameter updates.
1. Memory Growth (The “Better Notes” Approach)
Systems like GenericAgent and ReasoningBank represent this tier.
GenericAgent: Evolves by converting verified trajectories into reusable Standard Operating Procedures (SOPs) and executable code. It grows its tool inventory and factual archives but does not change its base reasoning engine.
ReasoningBank: Uses MaTTS (trajectory-scaling) to distill high-level reasoning from successful and failed attempts. It retrieves these at test time but remains a sophisticated retrieval-augmented system rather than a learning system.
2. Policy-Learned Management (The Learned Controller)
This tier introduces learning not to the base Large Language Model (LLM), but to the controller managing it.
MemRL: This system treats memory retrieval as a value-based decision problem. It stores experiences as Intent-Experience-Utility triplets and uses Bellman-style temporal-difference learning to update the “utility” of specific memories. Even when the LLM is frozen, MemRL outperforms standard RAG because it has a learned reuse rule.
AgeMem & Memory-R1: These systems replace static, heuristic-driven memory pipelines with trained behaviors. They use Reinforcement Learning to teach the agent exactly when to store, summarize, or discard information.
3. Internalization (True Learning)
This is the only tier where the “costume” comes off, and knowledge is moved into the policy’s parameters.
SKILL0: Employs a curriculum that progressively withdraws external skill scaffolds until the system can perform the task zero-shot.
SDAR (Gated Self-Distillation): Uses RL as a backbone to transfer underlying knowledge into the policy’s parameters. In testing, while skill-retrieval baselines dropped significantly in accuracy when skills were removed, SDAR maintained its performance, proving the knowledge had been genuinely internalized.
--------------------------------------------------------------------------------
Comparative Performance Data
Evidence from research papers such as MemRL and SDAR suggests that learned policies and internalization offer a significant advantage over static retrieval.
ALFWorld Transfer Accuracy:
MemRL (Learned Utility): 0.479
MemP (Memory without RL): 0.421
RAG Baseline: 0.336
Exploration-Heavy Settings: MemRL demonstrated a 56% improvement over MemP and an 82% improvement over no-memory baselines.
The Internalization Gap: In ALFWorld-3B tests, a skill-retrieval baseline (Skill-GRPO) scored 80.5 with skills but dropped to 60.2 without them. SDAR, by contrast, outperformed the augmented baseline even without external skill retrieval during inference.
--------------------------------------------------------------------------------
Industry Perspectives: The Two Camps
The debate over “self-evolution” is divided into two schools of thought regarding where agent improvement actually resides.
The Memory-First Camp
This group argues that durable external state is sufficient for “learning.”
Fimber Elemuwa (Mem0): Defines memory as a stateful read-write system; “memory is just a database that writes.”
Daniel Chalef (Zep): Argues against using RAG for memory, suggesting instead temporally-aware knowledge graphs and context assembly layers.
Harrison Chase (LangChain) & Charles Packer (Letta): View memory as a form of context that can be “poisoned” or modified to change the behavior of entire agent fleets.
The Learning-First Camp
This group argues that true evolution requires structural changes to the system’s decision-making engine.
Shengtao Zhang et al. (MemRL): Critique passive semantic matching, insisting on learned utility over memory usage.
Yi Yu et al. (AgeMem): Assert that memory management must be integrated into the agent’s policy rather than handled by auxiliary controllers or heuristics.
Zhengxi Lu et al. (SKILL0/SDAR): Focus on the internalization of knowledge into parameters to ensure performance survives the removal of external aids.
--------------------------------------------------------------------------------
Conclusion: The Hierarchy of Evolution
The research concludes that the field of self-evolving agents is not a binary of “real” or “fake” learning, but a layered hierarchy:
Level 1: Stored Experience: The agent grows its database.
Level 2: Structured Context: Experience is better organized and gated.
Level 3: Learned Policy: The rules for using memory are trained via RL.
Level 4: Parameter Internalization: Experience is distilled into the model weights.
For builders and auditors, the definitive test of an agent’s evolutionary claim remains the scaffold removal: if the agent’s performance gains survive the total deletion of its memory bank, it has achieved genuine internalization. If the gains vanish, the system is a stateful retrieval engine—effective, but not “self-learning” in the strong sense.







