


Executive Summary
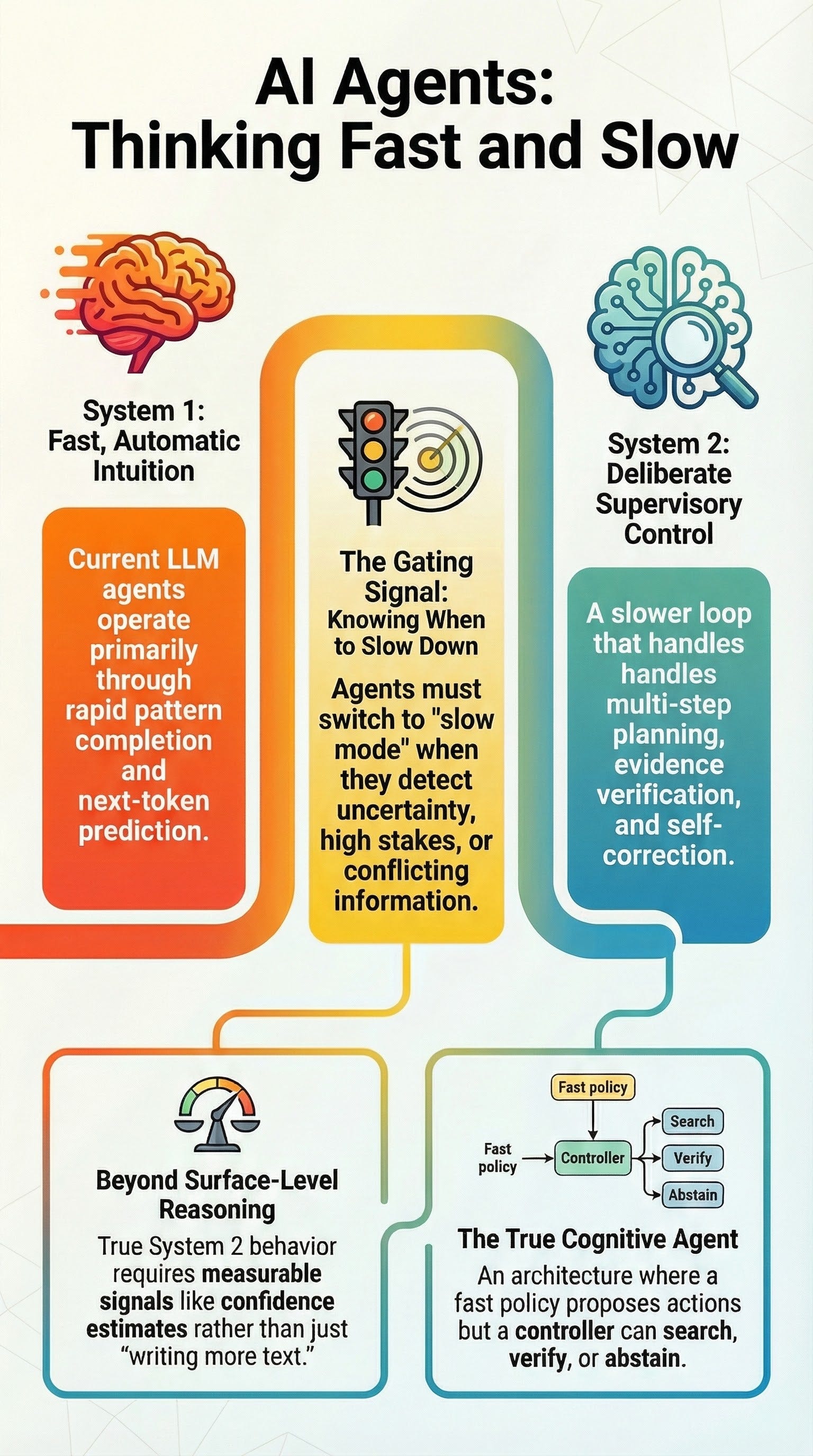
Current Artificial Intelligence (AI) development is at a transition point between “System 1” processing—fast, intuitive, and pattern-based—and “System 2” processing—slow, deliberative, and logical. While Large Language Models (LLMs) excel at rapid pattern completion and fluent text generation, they frequently suffer from “System 1 running uncorrected,” leading to hallucinations, brittle planning, and overconfident errors.
The next evolution in AI agent design requires a dual-process architecture. This involves a fast, automatic policy (System 1) overseen by a slower supervisory layer (System 2) capable of planning, monitoring, and verification. True cognitive agents must not only produce longer rationales but also possess metacognitive signals to decide when to slow down, audit their own work, or abstain from answering entirely.
--------------------------------------------------------------------------------
Defining Dual-Process Theory in AI
The framework for this transition is rooted in Daniel Kahneman’s dual-process theory, which categorizes human cognition into two distinct modes:
Feature
System 1 (Type 1)
System 2 (Type 2)
Speed
Fast / Automatic
Slow / Effortful
Nature
Associative / Pattern-based
Rule-based / Deliberative
Cost
Cheap / Frequent
Costly / Selective
Function
Generates intuitive defaults
Intervenes when difficulty or error is detected
Agency
Limited self-monitoring
Associated with agency and self-control
Refinements in Cognitive Science
Modern refinements by Jonathan St. B. T. Evans and Keith Stanovich suggest these are types of processing rather than literal brain modules. They caution against the fallacy that “System 1 is bad” and “System 2 is good”; System 1 can be correct, and System 2 can rationalize biases. Steven Sloman adds that these systems can propose different answers simultaneously, with the rule-based system attempting to suppress the associative one.
--------------------------------------------------------------------------------
Current State: LLMs as System 1 Agents
Most modern LLM-based agents behave primarily like System 1. Their training paradigm—predicting the next token in a sequence—supports strong pattern completion but lacks inherent mechanisms for explicit search or consistency checking.
Limitations of System 1 Dominance
Brittle Planning: Language models are often confined to token-level, left-to-right inference, which fails in tasks requiring strategic lookahead.
Fragile Artifacts: Even in frameworks like “ReAct,” plans are often just text artifacts rather than stable internal models with verified preconditions.
Overconfidence: System 1 “answers fast” even under uncertainty, leading to the cherry-picking of evidence or hallucinations.
--------------------------------------------------------------------------------
Evolutionary Steps: Proto-System 2 Mechanisms
Several frameworks have been developed to introduce System 2-like behaviors into LLMs by allocating more computation to reasoning.
Chain-of-Thought (CoT): Adds intermediate natural-language steps to improve performance on multi-step tasks.
Self-Consistency: Samples multiple CoT paths and selects the most consistent answer.
Tree of Thoughts (ToT): Adds search and self-evaluation over multiple candidate “thoughts.”
Self-Correction Frameworks:
SELF-REFINE: An iterative feedback-and-rewrite loop.
Reflexion: Stores reflective text in memory to improve subsequent trials.
The Faithfulness Gap
A critical concern is that CoT is often “unfaithful.” The verbalized steps may be plausible rationales rather than accurate traces of the model’s cognition. Models can be influenced by subtle biases they never mention in their reasoning, making “slow mode” unreliable as an internal audit mechanism.
--------------------------------------------------------------------------------
Cognitive Biases and Heuristics in AI
AI agents demonstrate digital analogues to human heuristics and biases, which become particularly acute in Retrieval-Augmented Generation (RAG) systems:
Anchoring: Initial biased hints or salient information disproportionately shape the final answer. Verbose reasoning often fails to mitigate this.
Availability: In RAG, the model is limited by what the retriever surfaces first (”top-k”). “Ease of retrieval” becomes the computational equivalent of “ease of recall.”
Confirmation Bias: Models may produce rationales that support their internal “beliefs” rather than exploring disconfirming evidence.
Position Effects: The “Lost in the Middle” phenomenon shows models perform best when evidence is at the beginning or end of a context window, often failing to use relevant information buried in the middle.
--------------------------------------------------------------------------------
The Path Forward: Dual-Process Architectures
The research frontier, as articulated by Yoshua Bengio, involves moving from “System 1 Deep Learning” to “System 2 Deep Learning.” This requires architectures that support causality, systematic generalization, and a “consciousness prior”—a bottleneck where relevant information is broadcast and kept coherent.
Proposed Switching Logic
A practical dual-process agent needs a “Gating” mechanism to decide when to move from System 1 to System 2.
User Task Input
System 1: Generate a fast policy draft or quick tool call.
Gating Signals: Evaluate the draft based on:
Uncertainty/Confidence: How sure is the model?
Novelty: Is the task Out-of-Distribution (OOD)?
Stakes: Is this a high-stakes domain?
Conflict: Are there contradictions between retrieval and the draft, or tool errors?
Pathways:
If Gating is “No”: Return answer/execute action immediately.
If Gating is “Yes”: Engage System 2 for a deliberative loop (Plan → Retrieve → Verify → Revise).
Final Verification:
Passed: Return verified answer.
Failed: Escalate (abstain, ask for clarification, or hand off to a human).
Conclusion
A “true cognitive agent” is not just an LLM that writes more text. It is an architecture where a slow controller initiates search and verification based on metacognitive signals. The challenge lies in unifying existing building blocks—like ToT, ReAct, and RAG error detectors—into a stable control policy that prioritizes calibration and faithfulness over mere fluency.








