


Executive Summary
Selecting an AI agent framework in 2026 is no longer a simple tooling choice; it is a 12-month production commitment. Early data from industry leaders like Klarna and Sierra demonstrate that successful implementations can achieve an 80% reduction in query resolution time and automate the workload of hundreds of full-time staff. However, the cost of an incorrect platform choice is significant—typically resulting in a full stack rewrite at the six-month mark as costs escalate or reliability fails.
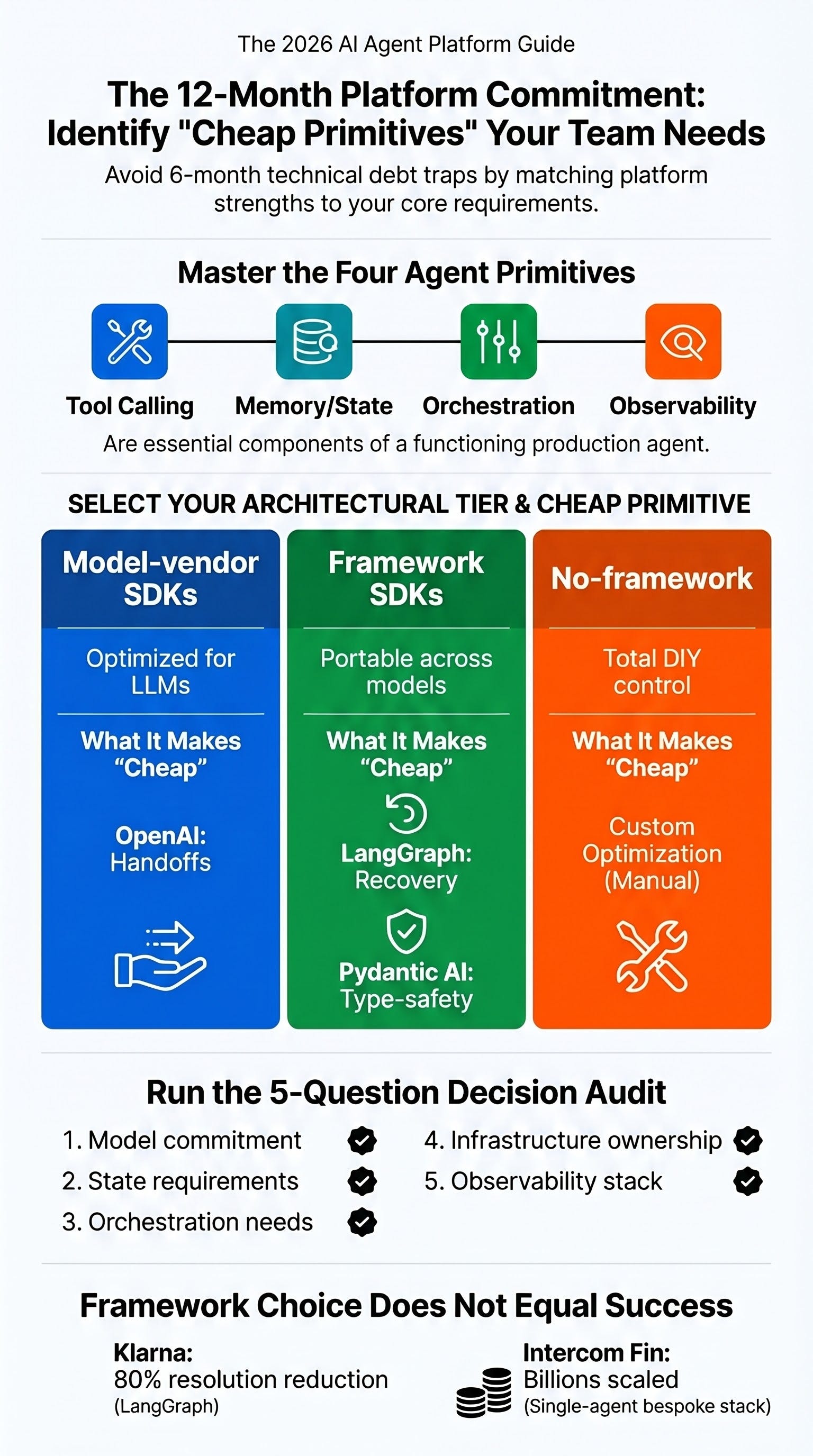
The strategic landscape is defined by four core primitives: Tool Calling, Memory/State, Orchestration, and Observability. The primary diagnostic for selection is determining “which primitives are cheap” within a given framework. While various tiers of platforms exist—from model-vendor SDKs to “no-framework” approaches—production success is ultimately determined not by the framework itself, but by tool design, retrieval quality, and evaluation discipline.
The Agentic Landscape in 2026
The definition of an “agent” has consolidated around systems where Large Language Models (LLMs) dynamically direct their own processes and tool usage to achieve goals based on environmental feedback. This “agentic loop” has moved from experimental buzzword to a cornerstone of Fortune 50 operations.
Market Momentum and Performance Benchmarks
Sierra: Valued at $15.8 billion with $150 million ARR, serving over 40% of the Fortune 50.
Klarna: Utilizes LangGraph to serve 85 million users, achieving the work-equivalent of 700 full-time staff and a 70% automation rate for repetitive tasks.
Intercom Fin: Operates at a scale of billions of conversations using a bespoke, single-agent architecture.
The Four Primitives of Agentic Design
Every help desk agent is built upon four foundational primitives. The choice of platform dictates which of these are natively optimized (”cheap”) and which must be custom-built.
Primitive
Description
Tool Calling
Reliable mechanisms for calling functions with typed parameters and structured results.
Memory and State
Persistence of information across turns, users, organizations, and specific incidents.
Orchestration
Managing the loop—deciding when a task is complete, when to hand off, or when to involve a human.
Observability
Real-time and retrospective insight into agent actions and decision-making logic.
The Three Tiers of Agent Frameworks
In 2026, the market has bifurcated into three distinct architectural approaches:
Tier One: Model-Vendor SDKs
Examples: Anthropic Claude Agent SDK, OpenAI Agents SDK, Google Antigravity 2.0.
Pros: Highly optimized for specific models; often include managed hosting options.
Tier Two: Framework-Vendor SDKs
Examples: LangGraph, Pydantic AI, CrewAI, Microsoft Agent Framework, Mastra.
Pros:* Portability across models; often offer advanced state management and orchestration patterns.
Tier Three: No Framework
Approach: Direct LLM API calls combined with utility libraries (e.g., Instructor, Pydantic).
Pros: Maximum control; avoids “abstraction tax” and debugging complexity.
Caveat: Recommended only for senior engineers who have previously shipped multiple agents.
Strategic Comparison: Which Primitives are Cheap?
Platform selection should be driven by the specific needs of the help desk workload. Each major framework prioritizes different capabilities:
Claude Agent SDK: Optimizes the loop and tool execution. It utilizes a “four-phase loop” (gather context, take action, verify work, repeat) and provides subagents for parallel work in isolated context windows.
OpenAI Agents SDK: Optimizes handoffs. It is designed for multi-agent architectures where different specialists handle specific tasks (e.g., refunds vs. FAQs), though it lacks built-in state persistence.
LangGraph: Optimizes crash recovery and human-in-the-loop gates. It treats agents as state machines with persistent checkpointing and “time-travel” debugging, making it ideal for complex, multi-day workflows.
Pydantic AI: Optimizes type safety. It ensures all inputs and outputs are strictly validated but is currently limited to single-agent architectures.
Production Case Studies and Architectural Insights
Analysis of successful 2026 deployments reveals that there is no “standard” architecture for success.
Klarna (LangGraph)
Klarna demonstrated that a framework can handle massive scale (2.5 million conversations) but also highlighted that framework choice does not dictate business strategy. When customer satisfaction signals shifted, Klarna used the framework’s flexibility to pivot back to a human-hybrid model without a full rewrite.
Intercom Fin (Bespoke/Single-Agent)
Despite the trend toward multi-agent orchestration, the leading vendor in help desk AI converged on a single-agent architecture. Intercom Fin avoids specialist routing and delegation patterns, proving that sophisticated internal pipelines can outperform multi-agent complexity at extreme scale.
Decagon and Sierra (Proprietary/Multi-Agent)
Both firms utilize multi-agent systems and proprietary runtimes. Decagon specifically employs “Agent Operating Procedures” to allow non-technical teams to define workflows, supported by a secondary “Watchtower” agent for quality assurance.
The Five-Question Decision Framework
To arrive at a defensible platform choice, teams must answer these five questions in order:
Model Commitment: Are you realistically committed to one model vendor (e.g., Anthropic Claude) for 12 months, or do you truly require the “optionality” (and abstraction tax) of a model-agnostic framework?
State Robustness: How much information must survive a process restart? Do you need session-level memory or crash-recoverable, multi-step workflow persistence?
Orchestration Shape: Do you actually need multi-agent handoffs, or can your workload be handled by a single sophisticated agent or isolated subagents?
Infrastructure Ownership: Will you use a managed vendor environment to handle scaling and sandboxing, or must you self-host to maintain control over networking and data residency?
Observability Integration: Does the framework export OpenTelemetry (OTel) cleanly to your existing stack, or will observability be an expensive retrofit?
Conclusion: Selection Rationale for Help Desk RAG
For a Python-based team building a chat-first help desk RAG agent in 2026, the Claude Agent SDK is identified as a strong default. This is based on its competitive performance in customer-service evaluations, built-in session management, and its use of subagents for parallel context isolation rather than complex multi-agent handoffs.
However, the ultimate success of an agent depends on the “3:00 AM Test”: Pick the platform that your team can understand in its bones when a production support queue is on fire. The framework’s role is to make the necessary primitives cheap so that engineering resources can be focused on the harder problems of tool design and retrieval quality.







