


Executive Summary
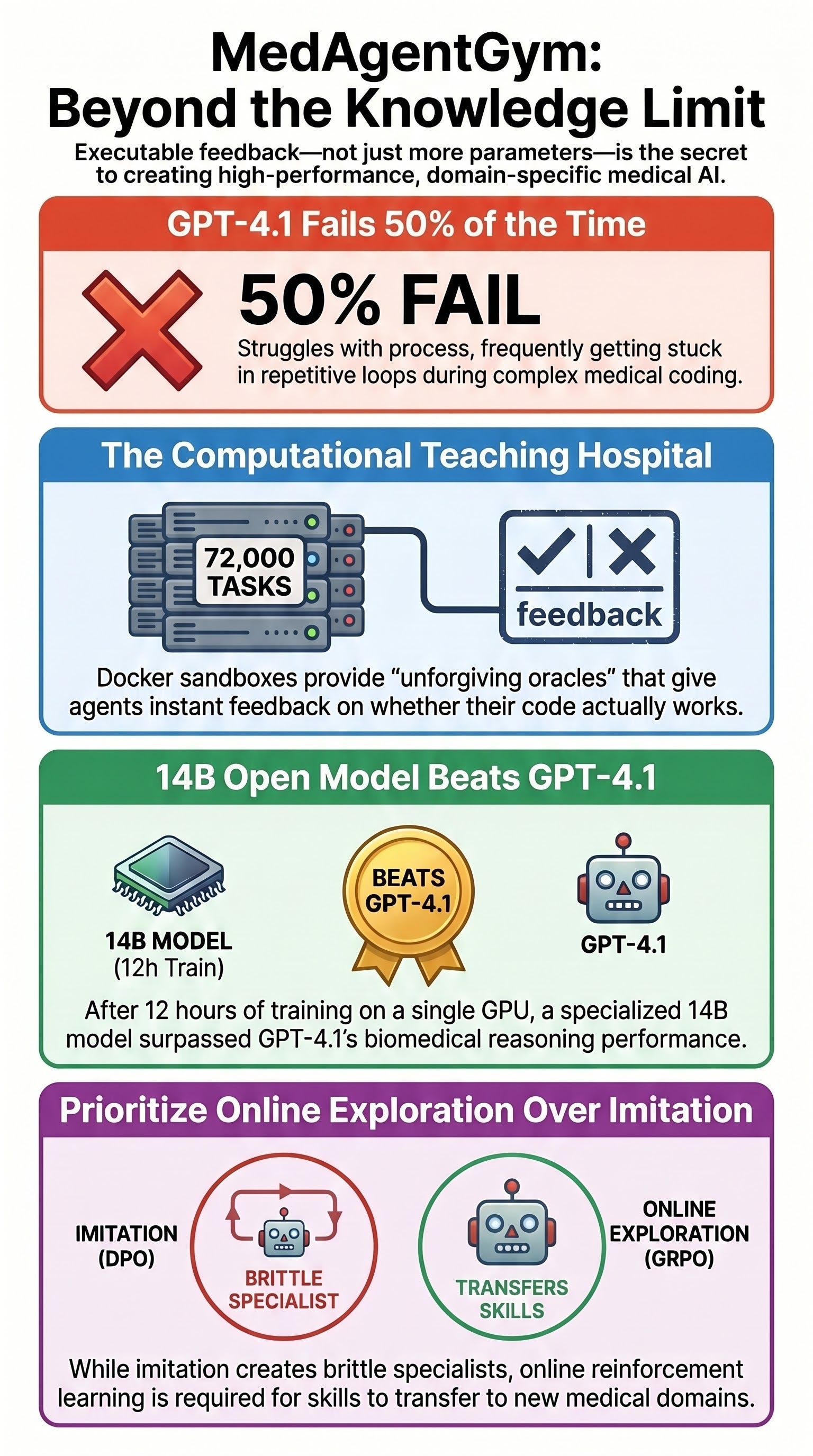
MedAgentGym represents a paradigm shift in medical AI training, transitioning from knowledge-heavy fine-tuning to environment-based agentic reinforcement. The framework utilizes a scalable, Docker-based sandbox containing 72,000 executable biomedical task instances to train models through verifiable feedback loops.
The primary findings of the research indicate that a 14-billion parameter open model, trained for fewer than twelve hours on a single GPU, can outperform GPT-4.1 on in-distribution biomedical coding benchmarks. However, the study also exposes a significant “transfer problem,” where models optimized through offline preference methods fail to generalize to out-of-distribution tasks. The most critical failure mode identified across models—including frontier systems—is the loss of adaptive control, manifesting as repetitive loops in approximately 50% of unsuccessful trajectories. The research concludes that dense, executable feedback and online exploration are essential for developing capable biomedical agents.
--------------------------------------------------------------------------------
The MedAgentGym Environment
MedAgentGym, also referred to in repositories as “A Scalable Agentic Training Environment for Code-Centric Reasoning in Biomedical Data Science,” treats medical AI development as an environment problem rather than a knowledge acquisition problem.
Technical Infrastructure
Docker Sandbox: Every task is wrapped in a containerized environment with pre-loaded biomedical packages and task-specific dependencies.
Action Space: Agents are restricted to four core actions:
request_info: For database lookups and schema reading.terminal: Standard command-line interface.code_execution: For running Python or SQL.debugging: A feedback channel that translates raw runtime errors into grounded natural-language explanations.
Verifiable Oracles: Success is determined by exact-match execution outputs, test-case accuracy, or learned verifiers, rather than human judgment.
Data Domains
The gym encompasses eight high-level domains anchored by major biomedical datasets:
Clinical Database Querying: SQL execution over MIMIC-III and eICU.
Clinical Note Analysis: Consistency checks on EHRCon.
Medical Computation: Bedside calculations via MedCalcBench.
Health IT: FHIR workflows on MedAgentBench.
Biomedical Software Engineering: Code generation via BioCoder.
Biomedical Data Analysis: Processing via BioDSBench and EHRSHOT.
Biostatistics & ML Predictive Modeling: Utilizing TREQS and N-PowerAI.
--------------------------------------------------------------------------------
Performance and Training Methodologies
The study demonstrates the efficacy of various training “stacks” on open-source models, specifically the Qwen2.5 series.
Comparative Performance (In-Distribution)
Model / Method
7B Parameter Score
14B Parameter Score
Zero-shot Base
16.89
20.12
Supervised Fine-Tuning (SFT)
53.87
63.92
SFT + DPO (Offline)
59.90
66.37
PPO (Online)
57.96
69.56
GRPO (Online)
62.17
71.42
GPT-4.1 (Zero-shot)
N/A
70.15
The 14B model trained via Group Relative Policy Optimization (GRPO) successfully surpassed GPT-4.1’s zero-shot performance within the gym’s specific distribution.
The Role of Debugging
Empirical results show that removing the debugging action significantly degrades performance across all task groups. This suggests that the environment’s ability to provide feedback on runtime errors is the primary mechanism for teaching the model adaptive control.
--------------------------------------------------------------------------------
Analysis of Failure Modes: “Stuck in Loops”
The research highlights a significant deficit in the “process management” of even the most advanced models.
Adaptive Control Failure: For GPT-4.1, the single largest failure mode is getting stuck in repetitive loops, accounting for 50.39% of all errors.
Error Breakdown:
Loops/Repetition: 50.39%
Runtime Errors: 30.39%
Compile Errors: 15.22%
I/O and Other Errors: 4.00%
Action Distribution: In open-ended tasks, 85.79% of actions are code-related and 12.46% are debugging. This suggests that failures occur not because the model lacks medical knowledge, but because it cannot effectively navigate the multi-turn coding process.
--------------------------------------------------------------------------------
The Generalization and Transfer Problem
While MedAgentGym demonstrates that small models can match frontier models in-distribution, the results for out-of-distribution (OOD) tasks are more nuanced.
OOD Results for the 14B Model
Base Score: 27.92
SFT + DPO: 27.91 (Zero improvement)
PPO: 37.32
GRPO: 47.02
Frontier Benchmark (GPT-o4-mini): 53.94
Key Finding: Direct Preference Optimization (DPO), an offline method, creates a “brittle specialist” that excels in-distribution but fails to transfer. Online exploration (PPO/GRPO) is necessary to close the gap on adjacent biomedical tasks.
--------------------------------------------------------------------------------
Philosophical Implications for Medical AI
Specialists vs. Generalists
The development of MedAgentGym sits at the center of a debate regarding the architecture of medical AI:
The Generalist Argument (e.g., Med-PaLM, Biomni): These systems emphasize multimodality (text, imaging, genomics) and dynamic tool retrieval across unseen subdomains to achieve zero-shot generalization.
The Specialist Argument: Proponents argue that domain-specific gyms are a safety-driven necessity. Medicine’s high-stakes nature and lack of forgiveness for hallucinations require principled adaptation through system engineering and verifiable feedback.
The Failure of Standard Medical Tuning
A critical insight from the paper is that specialized medical reasoning models (such as HuatuoGPT-o1-7B and Baichuan-M1-14B-Instruct) often underperform their own base models on MedAgentGym tasks. This indicates that standard fine-tuning on medical Q&A can actually reduce a model’s ability to perform practical, code-centric medical work.
--------------------------------------------------------------------------------
Critical Considerations and Limitations
Feedback Density: The success of the MedAgentGym approach is attributed to “dense, executable feedback”—a resource often missing in traditional LLM training “feedback deserts.”
Validation Gap: Critics (e.g., MedHELM, MedArena) argue that exam-style or code-centric benchmarks are insufficient to prove clinical readiness. They liken evaluating a doctor via MedQA to evaluating a driver via a written test.
Data Access: While the codebase is open, significant portions of the training data (MIMIC-III, EHRSHOT) are gated behind data use agreements and credentialing, complicating full independent replication.
Simulated Environment: The gym lacks the complexities of a real clinical setting, such as patient negotiation, consultation, and the inherent uncertainty where “exact-match” answers do not exist.







