


Executive Summary
The research into “Memento-Skills” introduces a paradigm shift in AI agent development, moving from static tool libraries to autonomous, self-evolving skill folders. By allowing a frozen large language model (LLM) to design, audit, and refine its own capabilities at deployment time—without updating the base model’s weights—the framework demonstrates significant performance gains. Notably, on “Humanity’s Last Exam” (HLE), the system more than doubled its accuracy from 17.9% to 38.7% by expanding its skill library from five to 235 entries.
The core finding is that agentic self-improvement is most effective when the workload contains reusable latent structures and verifiable feedback signals. However, the system relies on “metaprogramming without formal semantics,” creating a dependency on probabilistic routers and judges. While the framework offers a path to autonomous competence, its success is highly contingent on the “unit-test gate” that prevents recursive drift and ensures library integrity.
--------------------------------------------------------------------------------
Architectural Foundation: Skill Folders as Mutable Artifacts
Unlike traditional agents that rely on static prompts or hard-coded tools, Memento-Skills treats capabilities as persistent, addressable objects on a file system.
Composition of a Skill: Each skill is a directory containing:
SKILL.md: A declarative specification with YAML front matter.
Prompts: Instructions governing the model’s behavior for specific tasks.
Optional Scripts/Assets: Bundled code or external resources required to execute the skill.
The Audit Trail: Because skills are stored as physical files, the agent’s “knowledge” is transparent and auditable. Improvements or errors can be tracked through file-system mutations, functioning similarly to a pull request history.
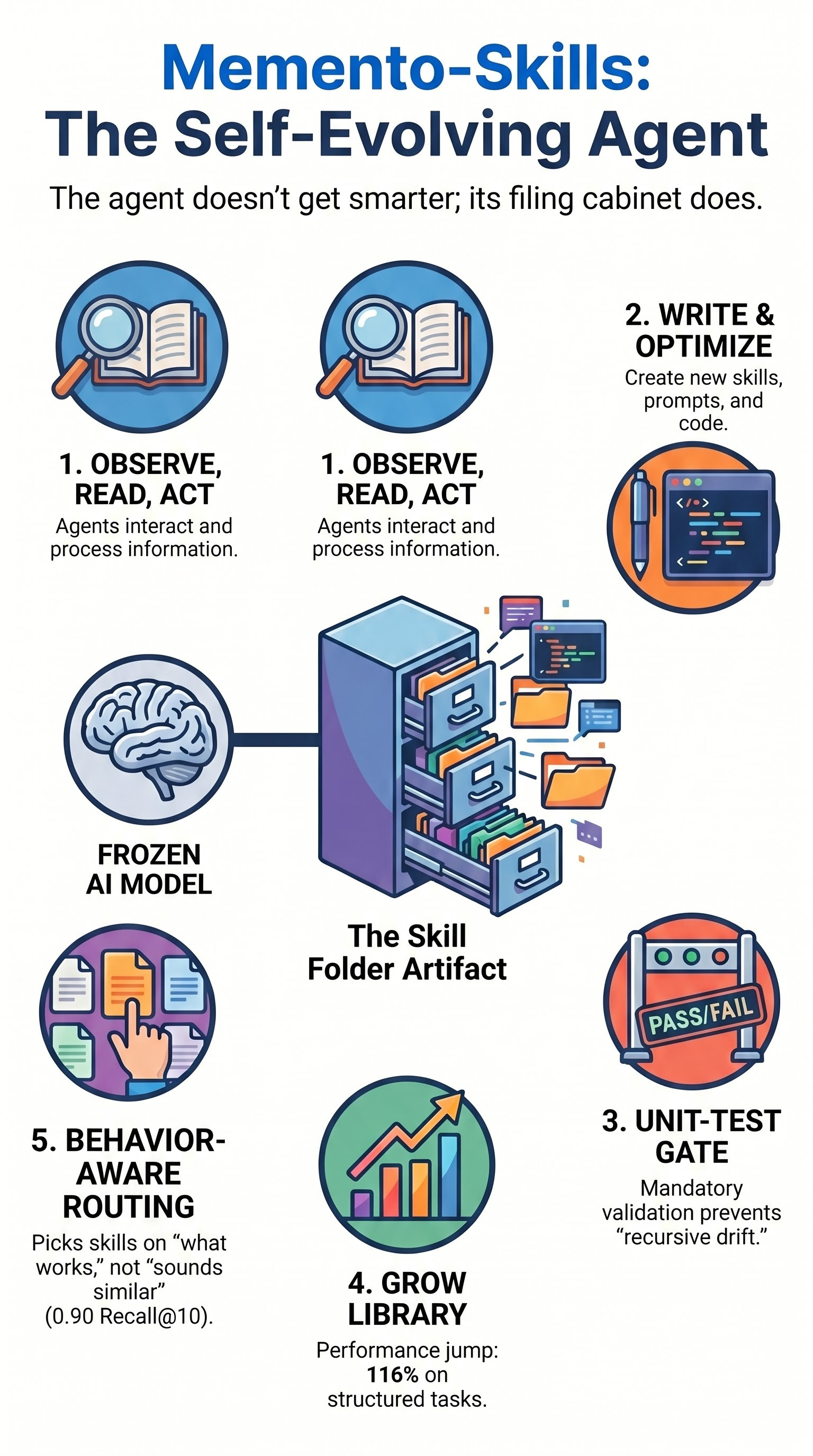
The Unit-Test Gate: To prevent the library from degrading, every mutation (edit or new skill creation) must pass a system-generated unit-test gate. If a mutation fails, the system attempts retries (up to a limit of K) before discarding the change.
--------------------------------------------------------------------------------
The Operational Loop: Observe, Read, Act, Feedback, Write
The Memento framework operates on a five-step cycle designed to identify and correct execution failures autonomously.
Observe/Read/Act: The agent identifies the task, retrieves the relevant skill, and executes the action.
Feedback: A judge (another LLM instance) evaluates the outcome.
Failure Attribution: If the task fails, a “target selector” analyzes the execution trace and the judge’s rationale to identify the specific skill responsible for the error.
Empirical Utility Decision:
In-place Optimization: If the failing skill still has a high utility score, the system rewrites the artifact to address the specific failure mode.
Discovery/Synthesis: If the skill’s utility falls below a certain threshold and sufficient evidence exists, the system either restructures the folder or synthesizes an entirely new skill.
--------------------------------------------------------------------------------
Behavior-Aware Routing
A critical challenge in managing an evolving library is ensuring the agent selects the correct skill for a given task. Memento-Skills moves beyond simple semantic similarity (finding skills that “sound like” the task) toward behavioral similarity.
Contrastive Retrieval: The router is trained as a contrastive retriever, optimizing for the skill most likely to work on a task based on previous behavior.
Training Data: The router was trained using a catalog of approximately 8,000 public skills, filtered for quality (minimum 500 GitHub stars).
Performance Metrics:
Recall@1: Improved from 0.32 (BM25) and 0.54 (Qwen3 embeddings) to 0.60.
Recall@10: Reached 0.90.
Success Rate: The “route-hit rate” climbed to 0.80 on real trajectories.
--------------------------------------------------------------------------------
Performance Analysis: HLE vs. GAIA Asymmetry
The effectiveness of Memento-Skills is not uniform across all benchmarks. The research highlights a significant “workload asymmetry” that dictates where autonomous design provides the most value.
Benchmark
Characteristics
Performance Gain
Improvement Type
GAIA
Diverse, heterogeneous, low pattern overlap.
52.3% to 66.0%
+13.7 points; limited cross-task transfer.
HLE
Structured subject categories (biology, physics).
17.9% to 38.7%
+116.2% relative gain; high skill reuse.
Key Takeaway: Recursive agent design is highly effective in “domain-clustered” environments where a skill refined on one question is likely to be reused on similar future tasks. It is less effective for one-off, heterogeneous consumer tasks where skills may never trigger a second time.
--------------------------------------------------------------------------------
Critical Risks and The “Skeptical Frontier”
Despite the performance gains, several factors limit the broad application of Memento-style architectures:
Retrieval Noise at Scale: While Memento managed 235 skills effectively, external research suggests that as libraries grow (e.g., to 34,000 skills), retrieval noise can cause performance to drop below no-skill baselines.
Recursive Drift: The system relies on a probabilistic judge. If the judge provides an incorrect rationale, the agent may overfit a skill to a “local failure mode,” baking a mistake into the library that persists in future executions.
Economic Overhead: There is a significant design cost involved in generating and testing skills. This overhead is only amortized in high-volume deployments.
Safety Degradation: Research indicates that agents learning from successful traces may inadvertently “unlearn” refusal behaviors, potentially compromising safety in high-risk scenarios.
Lack of Formal Semantics: Because the system stacks three noisy components—a probabilistic router, a probabilistic skill, and a probabilistic judge—it lacks the deterministic reliability of traditional compiler bootstrapping or metaprogramming.
--------------------------------------------------------------------------------
Synthesis and Conclusion
Memento-Skills represents a transition from agents as “fixed chefs with a static cookbook” to agents as “software maintainers.” Its primary contribution is not “self-improvement magic,” but rather a structured method for an agent to maintain its own executable memory.
For builders and architects, the decision to implement a Memento-style architecture should be based on three criteria:
Workload Structure: Does the task distribution have reusable latent patterns?
Feedback Quality: Is there a verifiable signal to keep the “unit-test gate” honest?
Deployment Volume: Is the volume high enough to justify the compute cost of autonomous skill design?
Where these conditions are met, Memento-Skills provides a robust framework for turning runtime failures into future competence without the need for expensive model retraining. Without these conditions, a static, human-curated library remains the more reliable and cost-effective choice.







