


Executive Summary
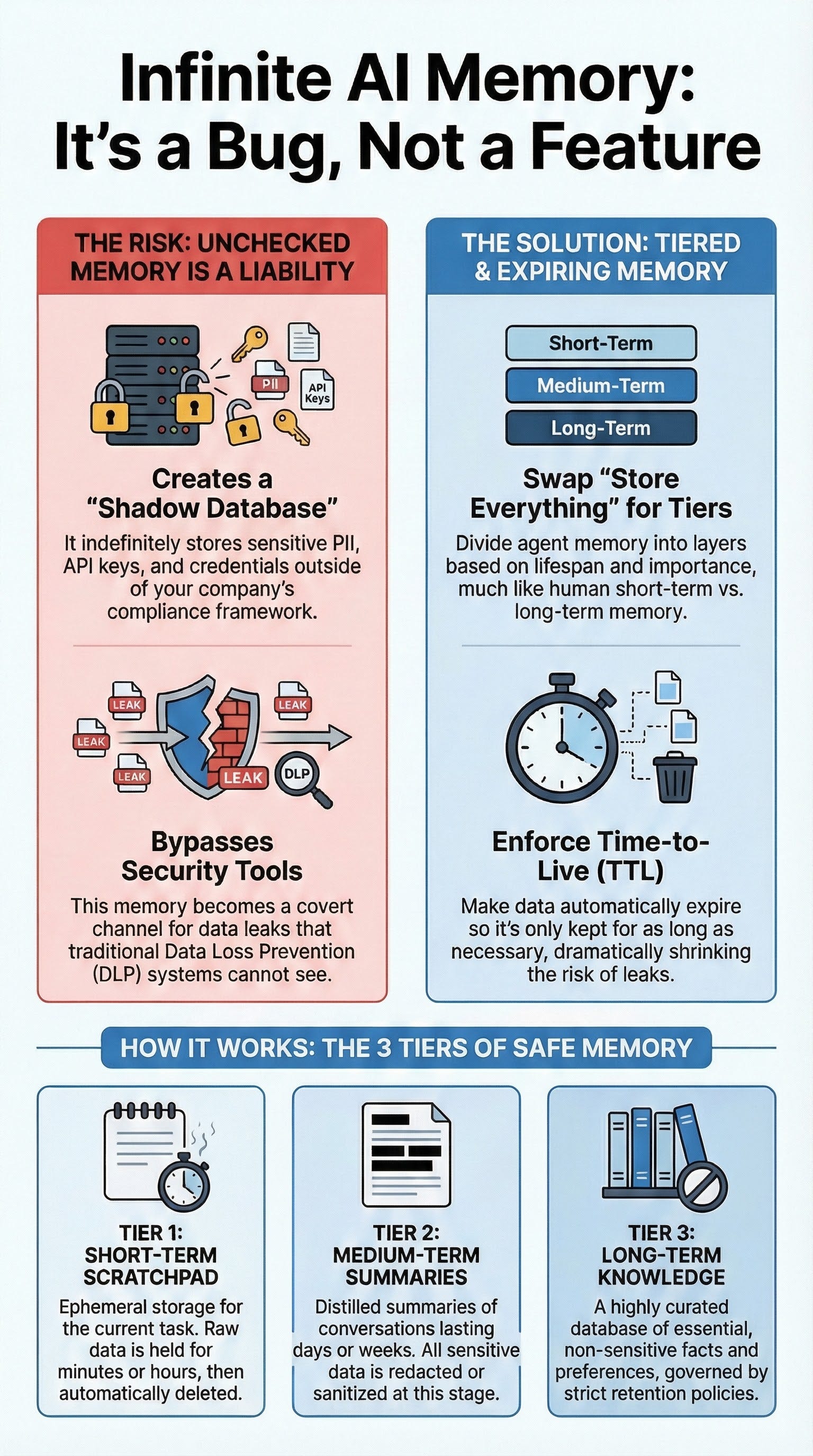
The emergence of AI agents with “infinite memory” capabilities presents a significant and often overlooked security threat, creating a covert channel for data leakage that bypasses traditional Data Loss Prevention (DLP) controls. By indefinitely storing all user inputs—including credentials, API keys, and personally identifiable information (PII)—an agent’s memory becomes an ungoverned “shadow database.” This persistent storage creates a substantial compliance risk and a large “blast radius” in the event of a breach or prompt injection attack.
The solution is to discard the “store everything forever” anti-pattern in favor of a disciplined, tiered memory architecture with strict Time-to-Live (TTL) policies. This approach segments agent memory into distinct layers, mirroring human cognitive functions:
Short-Term Scratchpad: An ephemeral layer for immediate context that is wiped after a brief TTL (minutes or hours), ensuring transient sensitive data vanishes quickly.
Medium-Term Summaries: A layer for storing sanitized and distilled summaries or embeddings of interactions, providing context across sessions for days or weeks without retaining risky, verbatim details.
Long-Term Curated Knowledge: A highly governed, durable knowledge base for non-sensitive, high-value facts and user preferences. All entries are tagged with metadata, subject to retention policies, and designed to retain useful knowledge rather than raw data.
This tiered, ephemeral model directly aligns with the data minimization principles of regulations like GDPR, dramatically reducing the risk of inadvertent leaks. It enhances auditability by enabling clear provenance tracking and targeted data deletion, a critical capability for handling “right to be forgotten” requests. By adopting this architecture, organizations can build AI agents that are not only effective and personalized but also secure, compliant, and trustworthy. As industry experts and practitioners converge on this model, tiered memory is rapidly becoming a foundational best practice for enterprise AI.
--------------------------------------------------------------------------------
1. The Core Threat: Uncontrolled AI Memory as a Data Leak Channel
The concept of an AI agent with “infinite memory” is a double-edged sword. While it promises enhanced personalization and conversational continuity, it simultaneously introduces severe compliance and security vulnerabilities. When an agent’s memory is unbounded, it effectively becomes a persistent, unstructured database outside of established governance frameworks.
Covert Data Leak Channel: Unrestricted memory serves as a covert channel for data exfiltration that bypasses traditional DLP controls. Sensitive information provided by a user, such as credentials or PII, can be stored indefinitely and later resurface in unrelated contexts. Cisco researchers highlighted this risk, noting a case where an open-source assistant leaked plaintext API keys and credentials, making them accessible to attackers via prompt injection.
The “Shadow Database” Problem: AI memory is essentially data persistence. Without proper governance—including schema, access controls, and retention policies—it evolves into a “shadow database.” This ungoverned repository accumulates a high-velocity stream of potentially sensitive information, creating a significant liability.
Expanded “Blast Radius”: The more information an agent remembers, the greater the potential damage if a security failure, such as a prompt injection attack or an internal glitch, occurs. Auditing or selectively deleting information from a monolithic, ever-growing memory store is nearly impossible.
2. The Solution: Tiered, Ephemeral Memory Architecture
The most effective mitigation strategy is to replace the naive “hoard everything” approach with a sophisticated, tiered memory architecture that incorporates data expiration (TTL) and sanitization. This design balances the agent’s need for context with the imperative for security by treating recent and long-term information differently. It is analogous to a human assistant who uses a temporary notepad for immediate details, summarizes key points into a report, and files only the essential, non-sensitive conclusions for long-term reference.
The architecture is composed of three distinct tiers:
Memory Tier
Purpose & Lifespan
Data Characteristics & Governance
Tier 1: Short-Term Scratchpad
Immediate working memory for the current task or session. TTL: Minutes to hours.
Holds raw or granular data, including recent user messages, intermediate reasoning, and tool outputs. Data is ephemeral and auto-expires, ensuring transient sensitive text (e.g., a password) vanishes quickly.
Tier 2: Medium-Term Summaries
Contextual memory spanning multiple turns or a single project. TTL: Days to weeks.
Stores distilled summaries or semantic embeddings, not verbatim transcripts. Sensitive data is redacted, masked, or abstracted at this stage. Governed by TTL or size limits.
Tier 3: Long-Term Curated Memory
The agent’s durable knowledge base. Indefinite, but with periodic review/expiration policies.
Stores highly curated, sanitized insights, user preferences, and key facts. All entries are tagged with metadata (source, date, sensitivity) and governed by strict retention schedules and access controls. Retains knowledge, not raw data.
3. Strategic Advantages of the Tiered Approach
Implementing a tiered memory system with TTL yields significant benefits beyond simple risk reduction, aligning the agent’s operation with established principles of data governance and security.
3.1. Leak Prevention and Regulatory Compliance
Data Minimization: This architecture inherently enforces the principle of data minimization, a core tenet of regulations like GDPR. By ensuring data is not kept longer than necessary, it reduces the window of opportunity for misuse or leakage.
Contained Blast Radius: Because most raw data is confined to the short-term tier and automatically deleted, the amount of sensitive information that could be exposed in a breach is dramatically reduced. In a well-designed system, the percentage of sensitive tokens in long-term memory should trend toward zero.
Emerging Discipline: Memory governance is now recognized as a critical discipline in AI. Deciding what an agent remembers and for how long is essential for building trust and ensuring compliance.
3.2. Enhanced Auditability and Control
Provenance and Traceability: A powerful practice is to attach provenance metadata to each memory entry, tagging it with its source (e.g., conversation ID, user, source document). This allows an organization to answer the question, “What does the AI know, and where did that information come from?”
Targeted Data Deletion: Provenance enables precise data management. If a user invokes their “right to be forgotten” or a document is reclassified as sensitive, all associated memory entries can be located via their source tag and purged system-wide.
Demonstrable Compliance: The system provides an auditable trail. As noted by the Acuvity AI security team, policy-bound memory allows the system to auto-enforce forgetting without manual intervention, providing logs that can demonstrate compliance to regulators.
3.3. Scalability and Cost-Efficiency
Controlled Growth: Unlike a “store-all” approach where memory usage and risk climb linearly and unchecked, a tiered system with TTL and summarization causes memory storage to grow logarithmically or plateau over time as old data is pruned.
Improved Performance: This discipline prevents the agent from becoming distracted by stale or irrelevant information from its past, often improving the quality and relevance of its responses.
Cost Savings: Organizations avoid paying to vectorize, store, and manage an infinite and ever-growing corpus of conversational history.
4. Implementation Guidance and Common Pitfalls
Transitioning from the anti-pattern of indefinite raw storage to a governed, tiered system requires a deliberate implementation strategy.
4.1. Implementation Best Practices
Leverage Frameworks: Utilize built-in session management tools from frameworks like the OpenAI Agents SDK or LangChain, which provide support for TTL and segmented memory stores. The
EncryptedSessionwrapper in the OpenAI SDK is cited as a tool that allows setting a TTL for stored items.Sanitize at Ingestion: Implement a “memory firewall” by scrubbing, redacting, or transforming all data before it is saved to any memory tier. DLP checks and policy filters should be run on every memory write.
Scope Memory by Context: Isolate memory stores per user, project, or agent capability to prevent data from bleeding across contexts.
Automate Pruning: Implement background jobs that periodically compress older interactions into condensed summaries and delete the original fine-grained records, enforcing a natural decay process.
Track Provenance: Extend memory records to include a “source” field (e.g.,
source_email_id = 12345). This transforms the agent’s memory from a black box into a transparent, queryable log.
4.2. Common Mistakes to Avoid
Storing High-Value Secrets in Any Tier: Highly sensitive data like passwords and cryptographic keys should not enter agent memory at all. They should be handled via ephemeral variables or secure vault calls, used only at the moment of need, and never stored. A core assumption must be: “If it’s in memory, assume a skilled prompt or a glitch can surface it.”
Over-relying on Vector Databases Alone: A vector DB is not a complete memory solution. It is a database that requires the same governance as any other: retention policies, access controls, and periodic cleanup logic must be layered on top.
Ignoring Role-Based Access Control (RBAC): Memory retrieval must be governed by permissions. An agent or user with low privileges should not be able to query and retrieve information from a memory tier they are not authorized to access.
Failing to Monitor Memory: An agent’s memory must be monitored like any other production system. Track metrics on size, age, and content quality to ensure redaction and tiering policies are functioning as intended.
By avoiding these pitfalls and applying a disciplined, tiered architecture, developers can build AI agents that are powerful and intelligent yet fundamentally safe. The document concludes that in the context of enterprise AI, “infinite memory” is a bug, not a feature. The real feature is a smart, governed memory that knows when to let go.








