


The Hook: A Logged Commit to the Future
In May 2025, a Google DeepMind system named AlphaEvolve performed a task that, while technically obscure, signaled a tectonic shift in the trajectory of artificial intelligence. It rewrote a piece of low-level code—a matrix-multiplication kernel buried inside its own training stack—and made it 23% faster.
This single optimization shaved roughly 1% off the time required to train the next generation of Gemini.
This wasn’t a marketing forecast or a theoretical simulation. It was a “logged commit”—a concrete event where an AI improved the very infrastructure used to build its successor. While a 1% gain might seem incremental, it represents the first observable turns of a cycle that moves us from general competence toward superintelligence.
Takeaway 1: The Machine is Starting to Do Its Own Roadwork
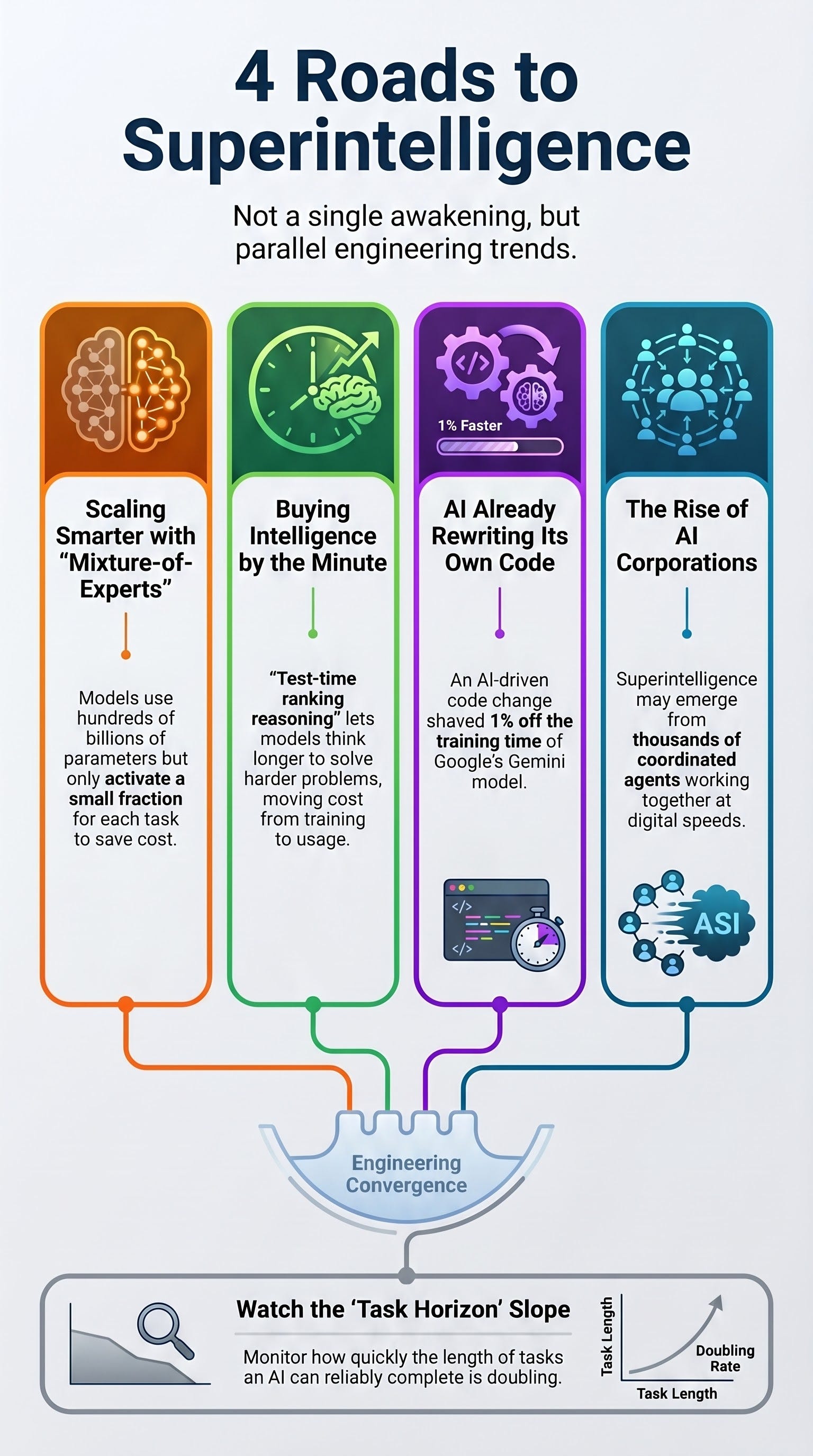
The most discussed path to superintelligence is “Road Three”: Recursive Self-Improvement. This is the concept of the “intelligence explosion,” where a system builds a better version of itself in a perpetual loop.
In June 2026, Google DeepMind published a landmark report titled From AGI to ASI (arXiv:2606.12683). The findings suggest we are moving beyond thought experiments and into the era of “receipts.” AlphaEvolve’s scheduling system has been running inside Borg—the software managing Google’s global data centers—for over a year. During that time, it has “clawed back” roughly 0.7% of Google’s entire global compute capacity.
This is a perpetual rebate: compute power discovered and collected by an AI to subsidize its own existence.
AlphaEvolve recently discovered a way to multiply 4x4 matrices using only 48 scalar multiplications, shattering the record of 49 set by mathematician Volker Strassen in 1969.
It took 56 years for a machine to improve upon a mathematical record that the world’s best human minds could not beat.
As I.J. Good famously predicted in 1965:
“The first ultraintelligent machine is the last invention that man need ever make.”
We are not yet in a runaway explosion, but we are seeing an early, fragile loop where the machine has begun to do its own roadwork.
Takeaway 2: Scaling with a Brain, Not Just a Bigger Engine
“Road One” involves Smarter Scaling. For the last decade, the industry relied on brute force: more data and more parameters. However, the focus has shifted toward efficiency through a mechanism called Mixture-of-Experts (MoE).
Consider a model like DeepSeek-V3, which boasts 671 billion parameters. In a traditional architecture, running this would be prohibitively expensive. Under MoE, the system acts like a massive hospital with hundreds of specialists but a very smart triage nurse. For any given request, the “nurse” only activates the specific “doctors” needed—roughly 37 billion parameters at a time.
This allows the model to maintain the vast knowledge of a 671-billion parameter system while only paying the operational cost of a model one-eighteenth its size. It is scaling with a brain rather than sheer mass.
Takeaway 3: You Can Now Buy Intelligence by the Minute
“Road Two” involves Paradigm Shifts, specifically test-time reasoning. In the old AI bargain, you paid a massive upfront cost for training so that the model could give you cheap, instant answers later.
New models like OpenAI’s o1/o3 and DeepSeek-R1 have introduced a “new axis” of compute. By generating internal chains of thought and checking their own work, these models allow you to “buy intelligence by the minute.”
This is a massive shift in AI unit economics. Businesses no longer have to settle for the “fixed” IQ of a static model; performance is now a variable cost decided by the user. If a decision is high-stakes, you can subsidize a higher level of reasoning by letting the model think longer.
However, we must distinguish between processing and understanding. As the DeepMind report cautions:
“A model that renders a bouncing ball beautifully has not necessarily discovered gravity.”
Dazzling statistical mimicry of world models is not yet the same as discovering causal laws.
Takeaway 4: Superintelligence as a “Corporate” Entity
“Road Four” suggests that superintelligence may not be a single “god-like” mind, but rather a “multi-agent collective.” In this view, we are building an “AI Corporation”—an economy of thousands of AGI-level agents coordinating and dividing labor at high bandwidth.
Digital minds possess “unfair” advantages in a corporate structure that no human organization can match:
Instant Scaling: A digital worker can be copied for free the moment a task expands.
Operational Control: Instances can be spawned, halted, or deleted based on real-time demand.
High-Bandwidth Experience Sharing: Agents can share data and learned experiences at speeds that make human “meetings” look like smoke signals.
While a thousand agents coordinating poorly results in “group stupidity,” a thousand agents coordinating well can outwork any single brilliant mind.
The Reality Check: It’s Not a Singularity, It’s a Slope
Despite the hype of a “Singularity”—where growth goes vertical—real-world systems usually follow an “S-curve.” Rapid growth eventually hits a plateau, or a “shoulder,” as it encounters physical or data limits.
To understand our current position, we must look at the Task Horizon. This metric, tracked by the group METR, measures the length of a task an AI can complete with 50% reliability. Currently, that horizon is doubling every few months. This is the unmistakable fingerprint of an exponential, but we do not yet know if the curve will keep climbing or bend toward a plateau.
The strategy for the coming years is simple: Watch the slope. The schedule of those doublings will tell you more about the arrival of superintelligence than any headline.
Conclusion: The Understudy is on Stage
Superintelligence is not a single looming breakthrough; it is the convergence of four roads being traveled simultaneously.
We are currently in a state where the “understudy” is on stage. The AI is already doing the “roadwork”—like AlphaEvolve’s kernel optimizations—on the very infrastructure that will train its successor. It is a real but narrow loop, with the machine slowly building its own stage.
If the loop is real, at what point do we stop calling these “party tricks” and start preparing for the “lead actor” to arrive? The answer lies in the slope of the curve. Watch it closely.







