


Executive Summary
The transition from single-call Large Language Model (LLM) interactions to autonomous agentic loops necessitates a fundamental re-evaluation of performance metrics, specifically on local “budget” hardware. This document synthesizes key findings regarding the “Agentic Loop”—the iterative cycle of thinking, tool execution, and observation—and its impact on latency, concurrency, and architecture.
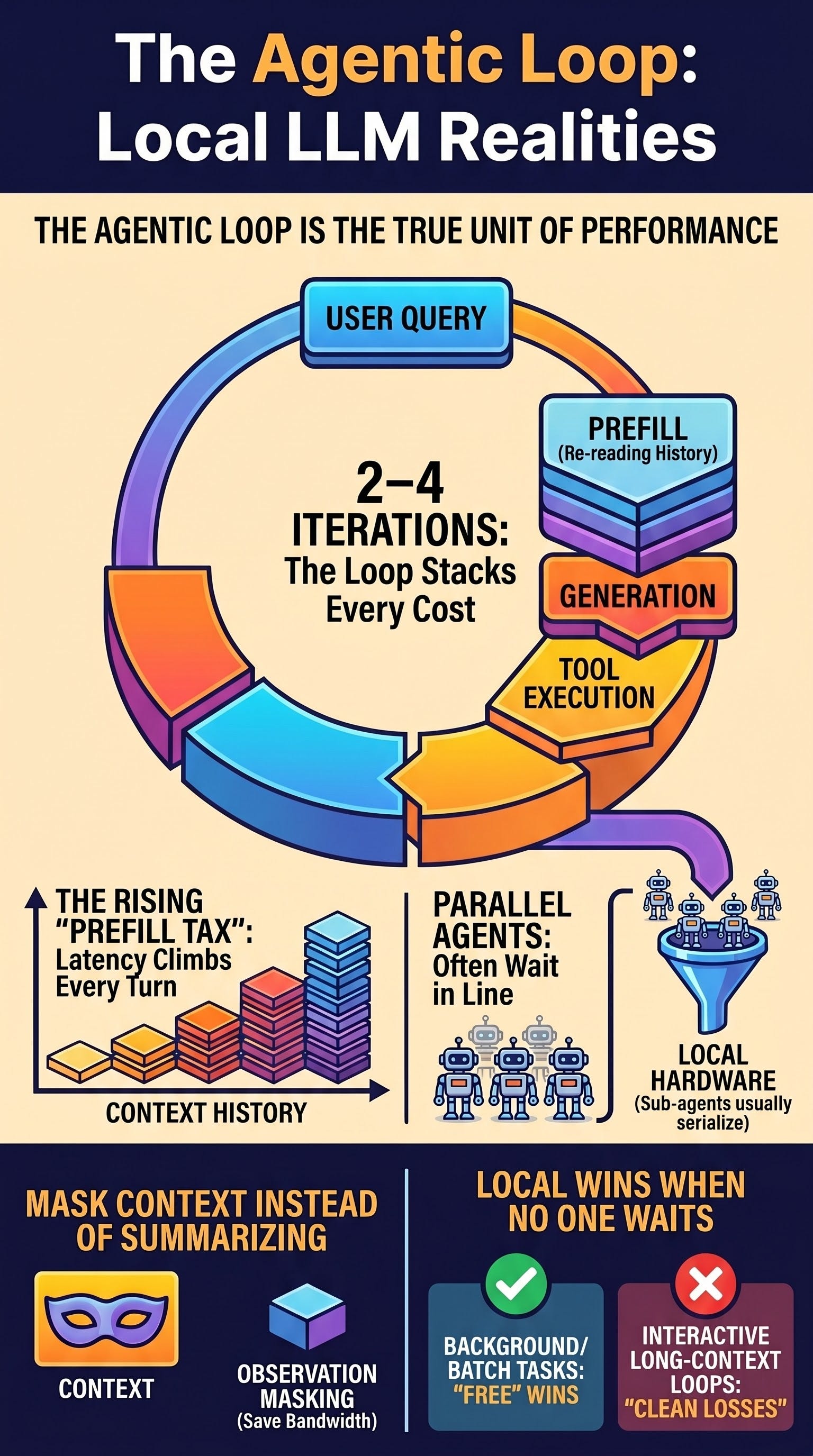
The critical takeaway is that the unit of performance is the loop, not the call. On local hardware, single-call benchmarks are deceptive because agentic workflows compound costs—particularly prefill latency—across multiple iterations. While porting agents to local environments is technically trivial (requiring only a base-URL change), the operational reality is defined by a “single-file line” at the model level unless specific serving stacks are utilized. Local orchestration wins in background, privacy-sensitive, and hybrid “local-and-cloud” configurations, but fails in high-latency interactive scenarios with expanding contexts.
--------------------------------------------------------------------------------
The Economics of the Agentic Loop
In an agentic framework, a single user query typically requires two to four iterations. Each iteration incurs three distinct costs that stack rather than average:
Prefill (First-token latency): The model reads the entire context before generating a response.
Generation: The model emits tokens for its next action or reasoning step.
Tool Execution: External operations (search, API calls, code execution) occur on the CPU side.
The Compounding Prefill Trap
On budget local boxes, prefill is the dominant bottleneck. Unlike a single-shot prompt, an agentic loop pays the prefill cost for every turn. Because the context grows with each iteration (as tool outputs and reasoning steps are added), the prefill cost rises throughout the task. A box that performs adequately on a one-shot benchmark may become unusable across a ten-step loop.
Performance Baseline (RTX 4090, Llama 3.1 8B):
Per-iteration latency: 1.8 to 3.5 seconds.
Total query time: 4 to 14 seconds (considered the “floor” for performance).
Hardware Variance: Prefill on a Strix Halo is approximately five times slower than on high-end budget configurations (”The Spark”).
--------------------------------------------------------------------------------
Concurrency and the Serving Stack
A common architectural error is assuming that fanning out sub-agents or parallel tool calls results in simultaneous execution. On local hardware, parallelism is often an illusion dictated by the serving stack.
Serialization vs. Batching
Ollama: Uses a First-In-First-Out (FIFO) queue. Parallel requests serialize, meaning five sub-agents will stand in a “single-file line,” negating the time-savings of a fan-out pattern.
vLLM: Employs continuous batching, allowing requests to genuinely overlap. The choice of serving stack is the single most important factor in determining orchestration efficiency.
The Concurrency Ceiling
The saturation point for a star topology of agents sharing a single context budget is defined by the formula:
N = W / m (Where N is the number of agents, W is the context window, and m is the per-message length.)
On budget hardware, the context window (W) is often constrained by memory, meaning this ceiling is reached much faster than in cloud environments. Reliability issues—such as malformed tool calls—exacerbate this by forcing retries that consume more of the limited context and processing power.
--------------------------------------------------------------------------------
Context Management Strategies
Long-running agentic loops eventually overflow the context window. The strategies used in cloud environments are often counter-productive when applied to local hardware.
The Failure of Cloud-Standard Summarization
The standard “cloud playbook” suggests using an LLM to summarize old history once a threshold (70–80% capacity) is reached. However, summarization is itself an inference call that requires prefilling the entire history at its maximum size. On low-bandwidth local boxes, this triggers the most expensive operation at the moment of highest context saturation.
The Local Alternative: Observation Masking
The research recommends observation masking and pruning for local agents.
Mechanism: Replace stale tool outputs with placeholders while keeping reasoning and actions intact.
Advantage: This is a rolling-window approach that requires no extra model calls, avoiding the “summarization tax” of slow prefill.
--------------------------------------------------------------------------------
Strategic Deployment Patterns
The viability of local agent orchestration depends entirely on the alignment of the workload with local hardware constraints.
Category
Performance
Rationale
Clean Win
Background/Batch
No human is waiting; latency is secondary to zero marginal cost and privacy.
Clean Win
Privacy-Bound
Local is the only compliant option for sensitive or air-gapped data.
Workable
Simple Assistants
Single-user, modest context, high-bandwidth GPU (e.g., MoE models).
Clean Loss
Interactive/Long Context
Human-in-the-loop waiting for minutes-per-answer due to compounding prefill.
Clean Loss
High Concurrency
Multi-agent bursts on a single box saturate memory and serializing queues.
The Hybrid Model
The most mature architecture is a hybrid local-and-cloud system. By utilizing an agent gateway, routine tool-calling steps are routed to a local Mixture of Experts (MoE) model (free and private), while complex planning steps are routed to cloud APIs. This treats the local box as the “floor” of the stack and the cloud as a “ceiling” used only when necessary.
--------------------------------------------------------------------------------
Conclusion
Local agentic orchestration is not a direct downgrade from the cloud; it is a different machine with a unique cost curve. Success requires shifting the focus from single-call benchmarks to loop-based instrumentation. Designers must match their orchestration patterns to their hardware’s bandwidth, prioritizing background tasks and observation masking to mitigate the inescapable costs of local prefill and serialized queues.







