


Executive Summary
The selection of a serving stack for local Large Language Models (LLMs) is a critical architectural decision that determines the responsiveness and reliability of agentic systems. For AI agents, traditional benchmarks like “peak single-stream tokens per second” are largely irrelevant. Instead, performance is dictated by Time to First Token (TTFT) and Concurrency management.
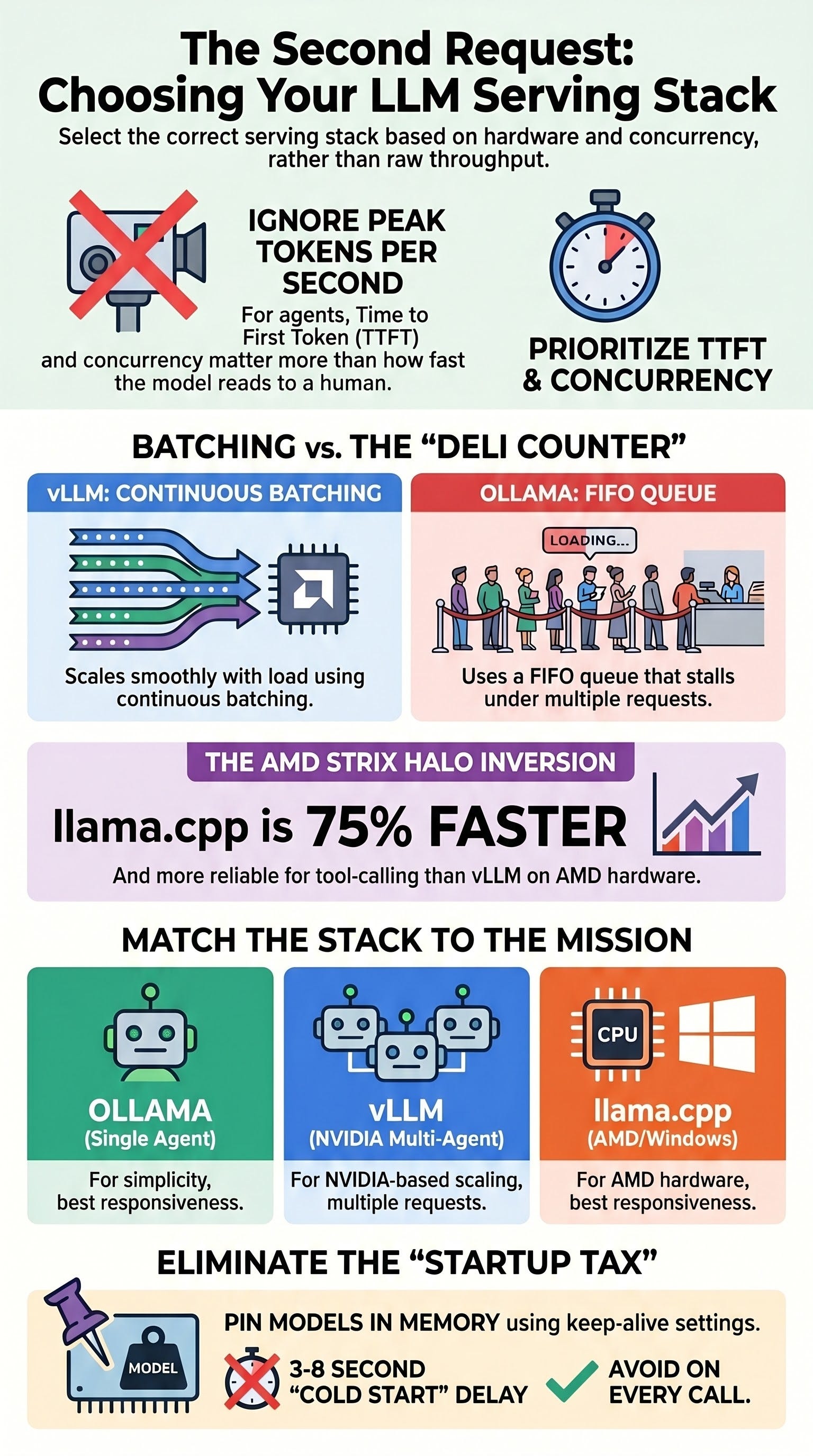
The current landscape features three primary stacks: vLLM, Ollama, and llama.cpp. While vLLM is the industry leader for high-concurrency environments due to its continuous batching and PagedAttention mechanisms, it is not a universal solution. Hardware constraints, specifically on AMD’s Strix Halo architecture, create a performance inversion where the lightweight llama.cpp outperforms vLLM by 75% while maintaining tool-call integrity. For single-agent workloads, Ollama remains the most efficient choice due to its superior TTFT. The optimal choice depends entirely on two variables: the degree of concurrent workload and the underlying hardware (NVIDIA vs. AMD vs. Apple Silicon).
--------------------------------------------------------------------------------
The Metrics That Matter for Agents
In the context of autonomous agents, traditional LLM benchmarks fail to capture the reality of the workload. Agents typically make dozens of short, sequential, or parallel tool calls.
Time to First Token (TTFT): This is the crucial responsiveness metric. Because agents operate in loops where one step waits for the previous output, high TTFT creates a bottleneck that compounds over the life of a task.
Concurrency: Multi-agent systems or agents utilizing parallel tool calls fire requests simultaneously. A stack’s “personality” is defined by how it handles the second request while the first is still processing.
The Throughput Fallacy: Peak tokens per second matters for human reading speeds, which were “solved a generation ago.” For agents, the delay in initiating a response is the primary killer of performance.
--------------------------------------------------------------------------------
Comparative Analysis of Serving Stacks
The following three stacks dominate the 2026 landscape, each handling concurrency and memory management through different architectural philosophies.
1. vLLM: The Concurrency Leader
vLLM is designed for high-load environments, primarily on NVIDIA hardware.
Continuous Batching: Instead of finishing one request before starting the next, vLLM weaves multiple requests into the same GPU operations token-by-token.
PagedAttention: This treats key-value (KV) cache like paged virtual memory. It reclaims roughly 40% more memory during bursts by dynamically allocating space rather than holding rigid blocks.
Performance Scaling: Benchmarks on Llama 3.1 8B show throughput scaling from ~485 tokens/sec at 10 concurrent requests to ~920 tokens/sec at 50 requests.
2. Ollama: The Single-User Specialist
Ollama is optimized for ease of use and low-latency single-stream generation.
FIFO Queueing: Ollama processes requests through a “First-In, First-Out” queue. It lacks continuous batching, meaning concurrent requests run sequentially.
Performance Plateau: Under load, Ollama’s throughput flattens. At 10 concurrent requests, it delivers ~148 tokens/sec, only increasing to ~155 tokens/sec at 50 requests—a 16x to 20x gap compared to vLLM at peak.
The “Deli Counter” Problem: A single long request (e.g., 32k tokens) at the front of the queue blocks all subsequent agent calls.
3. llama.cpp: The High-Performance Core
Known for its C++ core, llama.cpp is exceptionally fast for single streams but struggles with multi-user scaling.
Head-of-Line Blocking: Because it lacks dynamic scheduling, TTFT climbs exponentially as requests wait in a linear line.
Hardware Versatility: It is currently the preferred backend for AMD hardware and Vulkan-based environments.
--------------------------------------------------------------------------------
The Concurrency Crossover
The “best” stack changes based on the number of simultaneous requests. Research indicates a clear “TTFT Crossover” point:
Load Scenario
Top Performer
TTFT Comparison (Llama 3.1 8B)
Single User
Ollama
45ms (Ollama) vs. 82ms (vLLM)
10+ Concurrent
vLLM
~80ms P99 (vLLM) vs. 3,200ms (Ollama)
The gap widens sharply above four simultaneous requests. Since a single agent with parallel tool calls effectively acts as a “crowd,” vLLM becomes necessary earlier than many developers anticipate.
--------------------------------------------------------------------------------
Hardware-Specific Constraints and Inversions
The recommendation to use vLLM for concurrency assumes a CUDA (NVIDIA) environment. On other hardware, the advice “inverts.”
The AMD Strix Halo Riddle
On AMD’s Strix Halo (specifically the gfx1151 iGPU), vLLM is currently suboptimal:
Software Immaturity: vLLM requires building from source against nightly ROCm SDKs and specific patch sets.
Tool-Call Bugs: Tracked as
vllm#40785and#40787, vLLM on this hardware suffers from tool-call parser bugs where tags split across deltas, leading to argument corruption.The llama.cpp Advantage: On the same AMD hardware, llama.cpp is 75% faster on decode (7.5 vs 4.3 tokens/sec) and provides clean, verified tool calling via the Vulkan or ROCm backends.
Apple Silicon Optimization
MLX Backend: For M-series Macs, the MLX framework is the fastest path. Ollama (v0.19+) uses MLX, delivering ~130 tokens/sec on an M4 Pro (compared to 43 on legacy Metal).
vllm-mlx: For concurrency on Mac, a specific
vllm-mlxport exists to bring PagedAttention to Apple Silicon, maintaining stability past 10 parallel requests.
--------------------------------------------------------------------------------
Operational Configuration and Maintenance
Properly maintaining a serving stack requires balancing memory against responsiveness.
Keeping Models Warm:
vLLM holds models resident by default (8.7s startup).
Ollama unloads models after an idle window. To prevent this,
OLLAMA_KEEP_ALIVEmust be set to-1.Trade-off: A pinned model consumes both weights and KV-cache memory indefinitely, competing with other system resources on budget hardware.
Preventing Crashes in vLLM:
Two critical flags must be tuned:
gpu-memory-utilization(recommended at ~0.90) andmax-model-len.Failure to leave room for KV-cache growth under concurrent load will cause the process to crash.
--------------------------------------------------------------------------------
Decision Matrix for Stack Selection
Because all three stacks typically expose OpenAI-compatible APIs, the choice is reversible and should be based on current hardware and load.
Hardware
Workload
Recommended Stack
Key Reason
NVIDIA (CUDA)
Single Agent
Ollama
Lowest TTFT (45ms); simple setup.
NVIDIA (CUDA)
Multi-Agent / Team
vLLM
Continuous batching; stable P99 latency.
AMD (Strix Halo)
Any
llama.cpp
75% faster; clean tool-calling (no parser bugs).
Apple Silicon
Single Agent
Ollama (MLX)
3x performance jump over Metal backend.
Apple Silicon
Multi-Agent
vllm-mlx
Stable concurrency past 10 parallel requests.
Final Insight: The right serving stack is not the one that wins a generic benchmark; it is the one that survives the second request on the user’s specific hardware with the tool-calling reliability required for autonomous loops.







