


Executive Summary
This document provides a comprehensive analysis of the shift from standard chatbot interactions to agentic loops, focusing on the specific hardware demands and economic implications of running AI agents locally. The core premise, explored through the “Poor Man’s Spark” initiative, suggests that for agentic workloads, the high-cost hardware benchmarks typically prioritized for chatbots—such as peak tokens per second—are secondary to time-to-first-token (TTFT), memory capacity, and concurrency.
The analysis reveals that while agents consume 5 to 50 times more tokens than chatbots, creating a compelling case for self-hosting to avoid variable API costs, the financial viability of local hardware is entirely dependent on the “duty cycle” or utilization rate. A hybrid model—leveraging managed APIs for primary tasks and local hardware for sensitive, high-volume, or offline work—emerges as the current industry center of gravity.
--------------------------------------------------------------------------------
1. The Agentic Workload vs. The Chatbot Standard
The transition from simple chatbots to autonomous agents fundamentally alters the stress placed on inference systems.
Structural Differences
Chatbot Interaction: A linear “one prompt in, one answer out” process. Work is completed in a single stream.
Agentic Loop: A multi-step process involving planning, tool execution, result analysis, reasoning, and self-correction. The loop only terminates when a task is completed or a step budget is exhausted.
Impact on Token Consumption
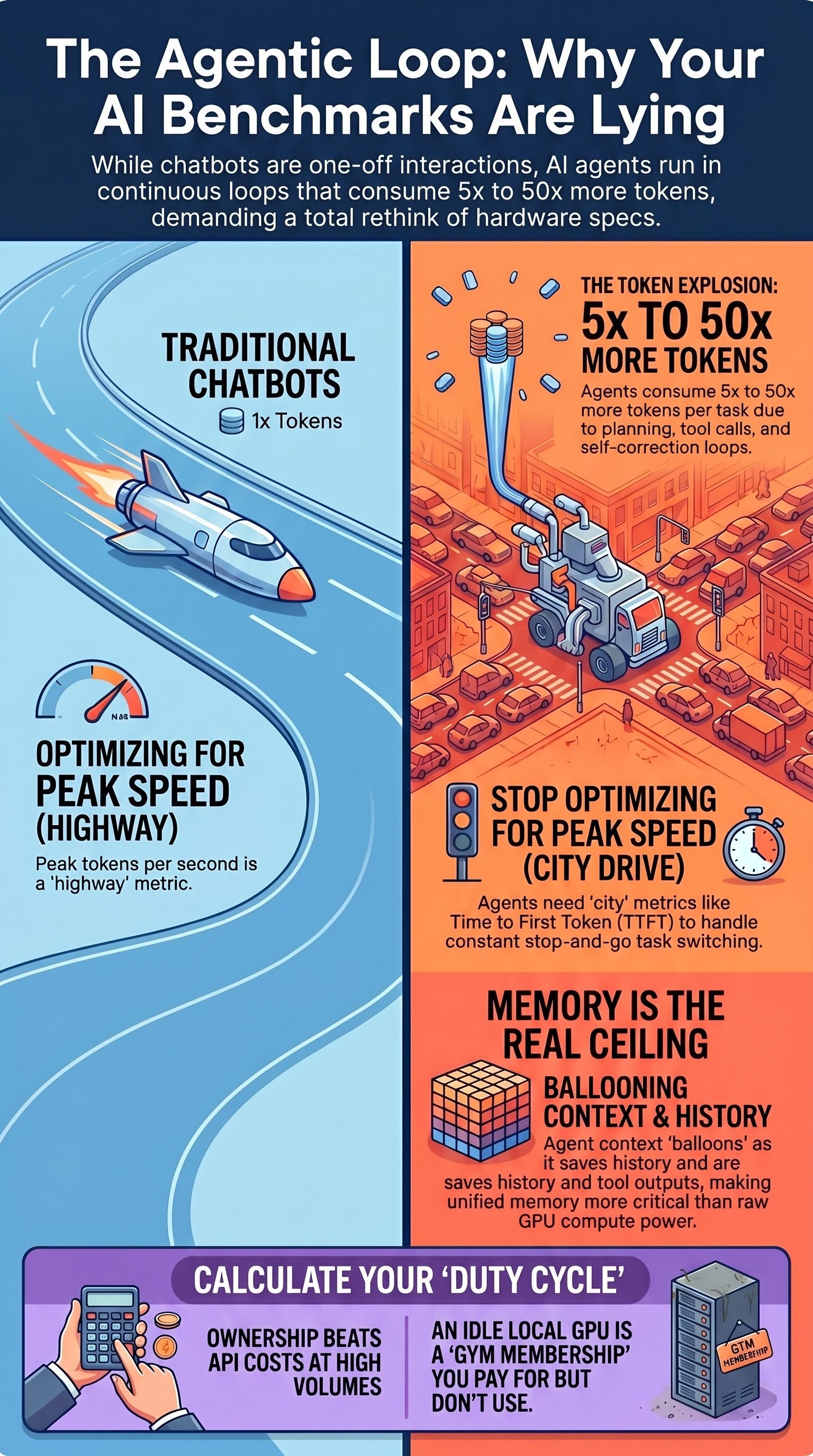
The “loop” is not merely a software feature; it is an economic driver. Agentic workloads consume tokens at a significantly higher rate than standard chat turns:
Volume Multipliers: Estimates suggest agents consume 5x to 30x the tokens of a standard chatbot interaction per task. Extreme cases report up to 50x consumption for autonomous tasks like code refactoring.
Cost Scaling: A single chatbot call may cost roughly 0.001**, whereas a multi-step agentic task can cost between **0.10 and $1.00.
Real-World Financial Risk: Documentation cites an instance of a single developer incurring $4,200 in API fees over one weekend for an autonomous refactoring project.
--------------------------------------------------------------------------------
2. Re-evaluating Hardware Performance Metrics
Because agents operate in a loop of short, bursty generations interleaved with CPU-side tool execution, traditional benchmarks are often misleading.
The “Intersections vs. Highway” Analogy
Peak Tokens per Second (TPS): This is the “cruising speed” or highway speed. It matters for chatbots delivering long streams of text.
Time to First Token (TTFT): This is the “on-ramp” or intersection. Because agents perform many small generations, they frequently encounter the fixed cost of starting a generation. If there are many “intersections,” top speed becomes irrelevant compared to how quickly the system can clear the red lights.
Critical Metrics for Agents
Metric
Importance for Agents
Description
Time to First Token (TTFT)
High
Dominates the total time in multi-step, short-generation loops.
Unified Memory/VRAM
High
Necessary to hold the “ballooning” context as history and tool outputs accumulate.
Throughput under Concurrency
High
Ability to handle many small tickets/tasks at once.
Peak Single-Stream TPS
Low
Rarely reached in bursty, tool-interleaved agentic tasks.
--------------------------------------------------------------------------------
3. The Case for Local Hosting
The move toward local hardware, specifically the “Poor Man’s Spark” approach, is driven by four primary and two secondary factors.
Durable Incentives
Privacy and Data Control: Prevents data leaks. A 2023 incident at Samsung involving proprietary semiconductor code being leaked to ChatGPT serves as a cautionary tale.
Regulatory Compliance: Essential for healthcare, finance, and government sectors where data is legally forbidden from leaving owned infrastructure.
Predictable Cost: Converts variable, per-token API billing into a fixed hardware cost plus electricity.
Resilience/Offline Operation: Ensures functionality in air-gapped or internet-deprived environments.
Secondary Incentives
Full Control: Freedom from content filters or sudden changes in provider terms of service.
Deep Integration: Easier access to local files, tools, and shells.
--------------------------------------------------------------------------------
4. The Economic “Duty Cycle” Trap
The financial argument for self-hosting is heavily dependent on utilization.
The Utilization Trap
An idle GPU represents a “sunk cost” liability. If a GPU sits at 10% load, the effective cost per token increases by roughly 10x. This trap is particularly punishing for rented cloud GPUs or high-end expensive hardware. The “Poor Man’s” thesis argues that cheap, owned hardware (like a $1,500 mini PC) mitigates this because the marginal cost is only electricity.
The Break-Even Discrepancy
Research sources vary wildly on when local hosting becomes cheaper than cloud APIs:
Conservative Estimate: Break-even occurs at 2 to 3 million tokens per day, but only when amortized beyond the first year.
High-Volume Estimate: Break-even is reached only at 360 million tokens per day (11 billion per month); below this, APIs are consistently cheaper.
Payback Scenario: On a moderate duty cycle (5 million tokens/day), a low-cost $1,500 rig could pay for itself in 5 to 6 months compared to hosted open-weight spend.
--------------------------------------------------------------------------------
5. Hardware Baselines: The Spark vs. The Poor Man’s Rig
The series uses the NVIDIA DGX Spark as the “measuring stick” for performance.
NVIDIA DGX Spark ($4,699):
CPU/GPU: GB10 Grace Blackwell superchip (20-core Arm Grace CPU + Blackwell GPU).
Memory: 128GB coherent unified memory.
Capability: Can run models up to 200 billion parameters due to lack of traditional VRAM limits.
The “Poor Man’s” Alternative (~$1,500):
Example: A Strix Halo box.
Key Feature: Offers the same 128GB unified memory “trick” at roughly a third of the price.
Strategic Advantage: By sacrificing peak performance irrelevant to agents, it achieves the same memory-heavy capacity needed for long-context agentic loops.
--------------------------------------------------------------------------------
Conclusion
The decision to run agents locally is not a binary choice between “better” or “worse” hardware, but a calculation of “duty cycle.” For high-volume, sensitive, or complex multi-step tasks, local hardware—specifically lower-cost rigs optimized for memory and latency rather than raw throughput—provides a sustainable alternative to the escalating costs of agentic API consumption. However, for light or inconsistent workloads, managed cloud APIs remain the lowest-cost and most efficient option.







